Python Pandas- Compare Two CSV files, based on that comparison update CSV file
- November 18, 2019
- Lorem ipsum dolor sit amet
- By Mousumi Bakshi
Sometimes we need to compare 2 CSV and get a list of common rows or common columns, that is a very common requirement.
But sometimes we also need to compare CSV files and based one comparison need to update CSV file. In this example I am going to elaborate that, hope that will help others.
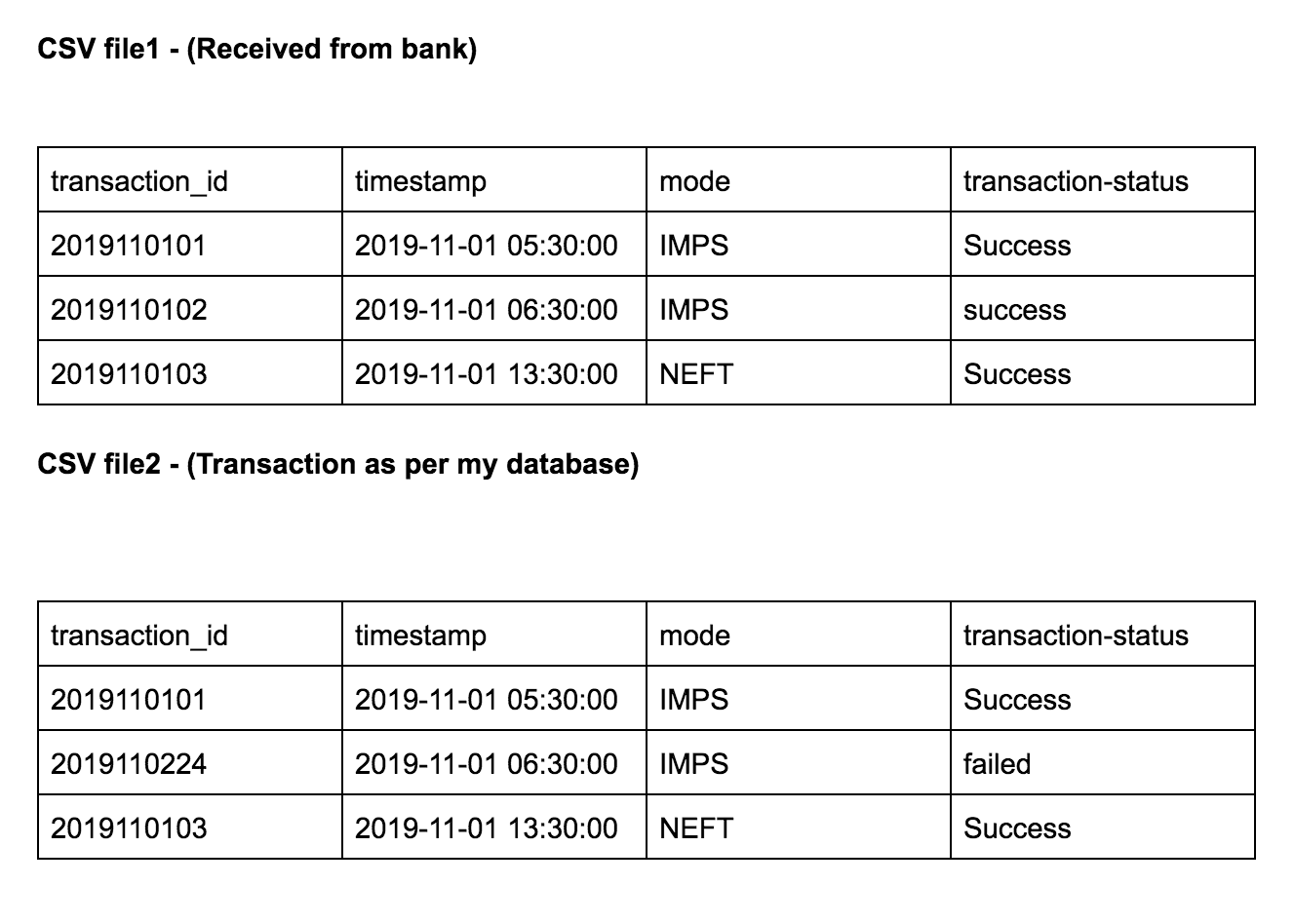
I got this requirement in “Reconciliation” module in one of my project, where One CSV I got from Bank where I can see all transactions happened in one day .
I have another csv where I have all transactions recorded in my database. So now we need to compare transaction with common id (Like transaction id ) and find out all transactions which are not present in our DB.
So let’s go
Now I have written one python class “csv_compare”.py
import pandas as pd def read_compare(): f1 = pd.read_csv('test1.csv') for index, row in f1.iterrows(): transaction_id=row['transaction_id'] search_status = find_and_match(transaction_id) if search_status == True: print('Matched') def find_and_match(transaction_id): print(transaction_id) f2 = pd.read_csv('test2.csv') index = f2[f2['transaction_id'] == transaction_id] print(len(index.index.values)) if len(index.index.values) > 0: status_col = 'status' f2 = f2.set_value(index.index.values[0], status_col,1) f2.to_csv('test2.csv', index=False) return True else: return False
In this class first I imported Pandas, then read 2 csv files and then I add one more column in first CSV (CSV1) name “status”. Fetching Each row of first CSV and If transaction id is present in CSV2 file then i Updated that row “Matched” in new column “status”
I have Runner class file “runner.py”
import csv_compare csv_compare.read_compare()